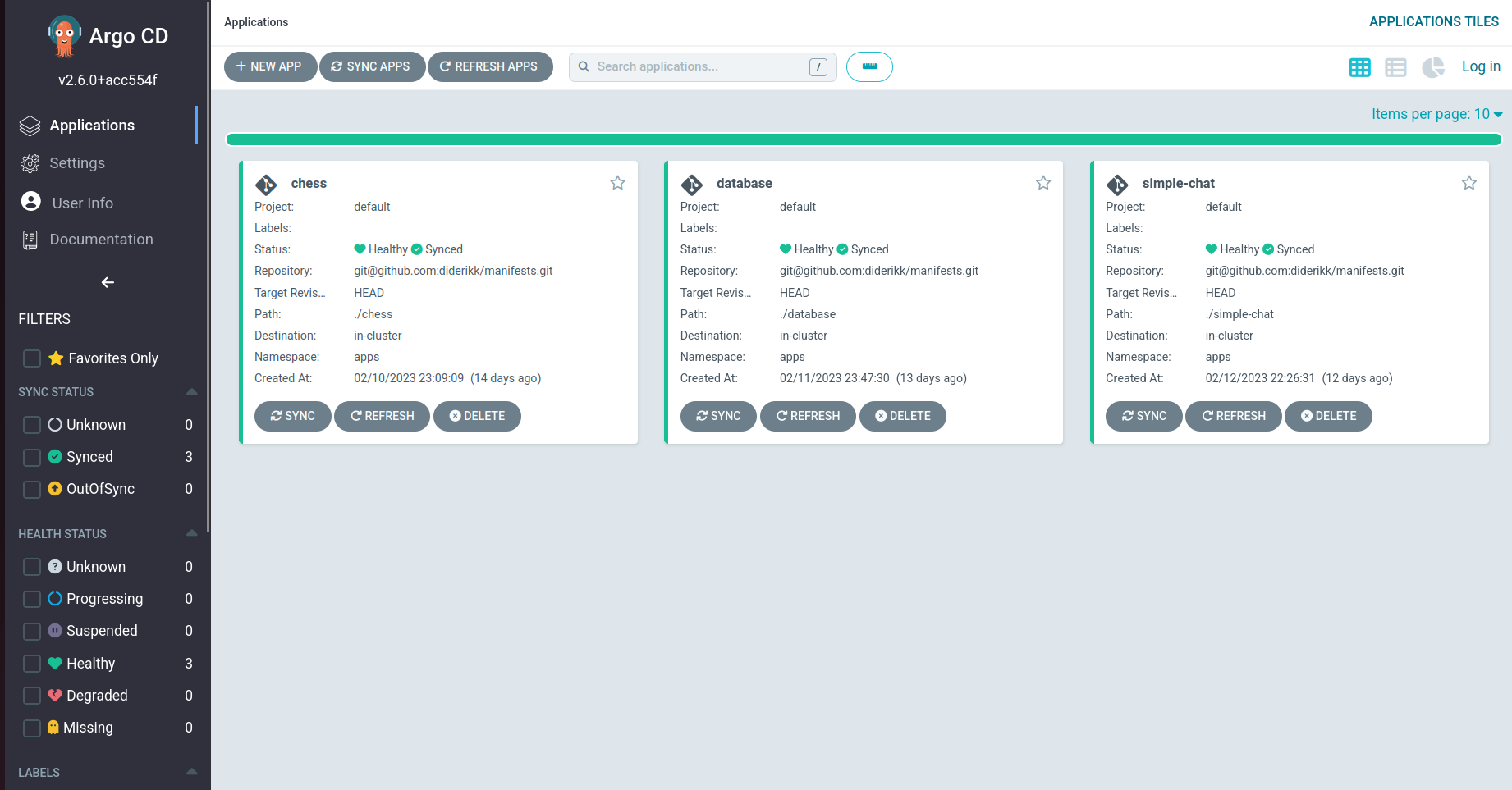
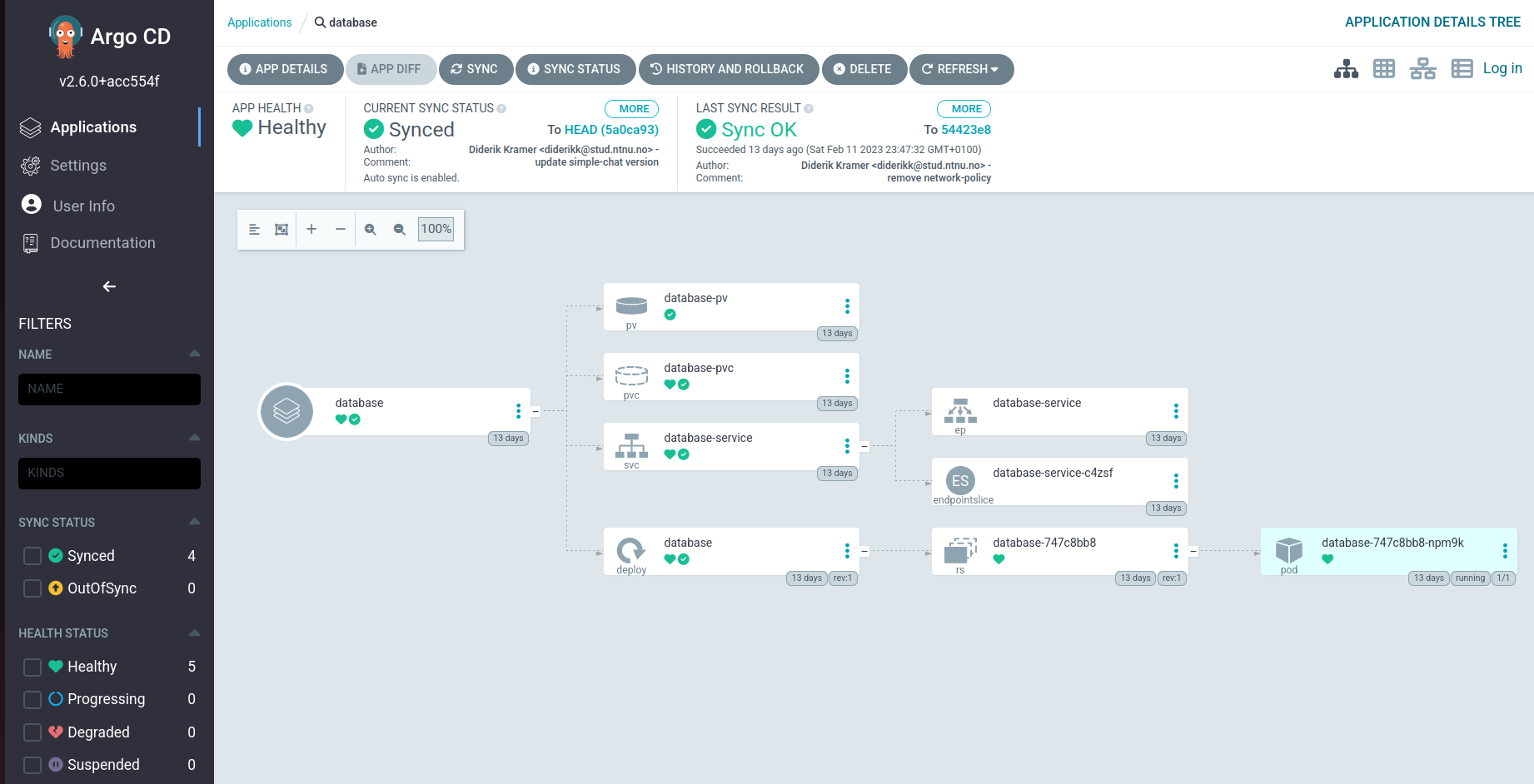
This series of notes is about my experience learning and configuring a Kubernetes cluster. Previously, I used a single Virtual Machine to host all my web applications. However, they have become cumbersome to keep track of and are hard to deploy and update. In addition, cloud technologies are in trend and something I want to get practical and theoretical experience on. This article will explain the infrastructure and setup to deploy my chess and simple chat applications.
2023-02-24 19:34:31.185772+00
ArgoCD is, by definition, "a GitOps continuous delivery tool for Kubernetes." (ArgoCD). It applies a pattern of using Git repositories as the source of truth for defining deployment states. I decided to install only the core version with minimal features onto the cluster, providing mainly the GitOps functionality. When needed, I can host the UI locally. Implementing ArgoCD requires connecting it to a GitHub repository and defining paths to folders containing manifests files that create deployments. A feature using ArgoCD is the ability to synchronize the repository automatically every three minutes, simplifying the deployment process. This functionality complements using GitHub as centralized storage for all my manifest files (except Secrets). Now I only need to push changes, and ArgoCD will reconfigure deployments after the sync period, removing the intermediary of manually applying the updated manifests to the cluster. In addition, it provides a UI that displays all resources used for deployment, replacing the GET commands in the Kubernetes CLI for manual status checks.
In order to deploy my applications, I required a Postgres database for their use. Since entities inside the cluster are the only ones using the database, it should not be open on an external port. The Service connected to the deployment will therefore be of type ClusterIP. Contrary to my other deployments, the database needs long-term physical storage (not memory), so I decided to use Persistent Volume (PV). There are different PV types, the simplest being local, which mounts the volume on a worker node. The Persistent Volume reserves a given amount of space on the node, which can be claimed by a Persistent Volume Claim (PVC) and mounted in a pod. To ensure consistency even when the nodes restart, I applied the PV with a Storage Class using reclaimPolicy of retain. In other words, when the cluster removes the PV, the reserved physical storage on the node can only be reclaimed manually (not by Kubernetes). After the Persistent Volume Claim has been approved and mounted on the pod under /var/lib/postgresql/data, the Postgres container image stays consistent on every restart.
apiVersion: apps/v1
kind: Deployment
metadata:
name: database
namespace: apps
labels:
app: database
spec:
replicas: 1
selector:
matchLabels:
app: database
template:
metadata:
labels:
app: database
spec:
containers:
- name: database
image: postgres:15.1
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "128Mi"
cpu: "250m"
ports:
- containerPort: 5432
envFrom:
- secretRef:
name: database-secrets
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: database-volume
volumes:
- name: database-volume
persistentVolumeClaim:
claimName: database-pvc
Updating environment variables becomes an issue using the retain reclaim policy because even when I delete the PV, the configurations of previous deployments are kept. This problem became apparent when updating the username, password, host, and database name environment variables. The only solution I found was manually reclaiming the reserved physical storage on the worker node and redeploying the database.
The last configuration I added before deploying the applications was a centralized access point into the cluster. Kubernetes calls this an Ingress. The documentation states, "You must have an Ingress controller to satisfy an Ingress. Only creating an Ingress resource has no effect.". Therefore, I first added an NGINX Ingress controller. NGINX provides all the required functionality, even for self-hosted clusters on bare metal, which do not have an inherent load balancer. Additionally, since I do not have a load balancer, the public ports the Ingress advertises have to be NodePorts which range from 30000 - 32767, which means I cannot use port 443 for HTTPS or port 80 for HTTP. A solution, as mentioned by the NGINX GitHub "Bare metal considerations", is to add a pure software-based load balancer.
After adding the Ingress Controller, I configured the Ingress. It provides mainly two functionalities; connecting external requests to application endpoints and TLS termination. The first consists of defining URL paths from external requests and forwarding them to the correct Service. Services expose pods to the rest of the cluster, providing an internal IP address and port for other cluster applications.
tls:
- hosts:
- elixirapi.me
secretName: tls-secrets
The second part of my Ingress handles TLS requests. TLS termination eliminates the need for each application to handle TLS and require a copy of the signed certificate and private key, which would require more configuration on each application. It simplifies HTTPS/WSS calls by removing encryption in the Ingress before forwarding the request to a Service and application.
Ingress provides security; using cryptography, TLS ensures authentication, integrity, and confidentiality. The defined paths only expose specific routes, providing more centralized control and minimalizing the attack vector on each application.
The first application I decided to deploy was the Chess application. Since I am using ArgoCD GitOps, the deployment process only consists of writing a bundle of manifest files and pushing them to GitHub. The final bundle included the following objects:
The Service object type used is ClusterIP, which only exposes inside the cluster. This type is sufficient since the Ingress will expose it externally later.
apiVersion: v1
kind: Service
metadata:
name: chess-service
namespace: apps
labels:
app: chess
spec:
type: ClusterIP
ports:
- port: 4000
selector:
app: chess
The main parts of the Deployment object are the image, probes, and resource limits. The image value is the path to my public DockerHub repository concatenated with the desired version tag. To update the deployed application in the cluster, I must build a new image locally, increment the version semantically (major.minor.patch), and push it to the remote repository. After that, I change the version in the manifest file to the incremented image tag, and ArgoCD resolves the rest. Probes are audits performed at certain stages of the deployment. My audits are HTTP requests that need to receive a response. I use it for readiness and liveness testing, meaning I check to see if the application is ready on startup and verify it continuously during the Running state. Lastly, even though Pheonix is a lightweight web server framework, I have added resource limits to prevent it from allocating too much memory and using too many CPU cycles. After creating the deployments, Kubernetes initializes pods (containers) of the application image and starts running.
apiVersion: apps/v1
kind: Deployment
metadata:
name: chess
namespace: apps
labels:
app: chess
spec:
replicas: 1
selector:
matchLabels:
app: chess
template:
metadata:
labels:
app: chess
spec:
containers:
- name: chess
image: diderikk/chess:v1.0.7
imagePullPolicy: IfNotPresent
resources:
limits:
memory: "512Mi"
cpu: "500m"
ports:
- containerPort: 4000
envFrom:
- secretRef:
name: chess-secrets
livenessProbe:
httpGet:
path: /api/hello/live
port: 4000
initialDelaySeconds: 30
periodSeconds: 3600
failureThreshold: 1
readinessProbe:
httpGet:
path: /api/hello/ready
port: 4000
initialDelaySeconds: 10
periodSeconds: 30
failureThreshold: 2
The second and last application I have deployed is Simple Chat. It requires a database to run, and as explained above, that is already made available inside the cluster. I only have to inject a database URL into the pod as an environment variable. Since I know the user, password, and database name, I only need the host, which is the Service address of database deployment. However, since the IP address of the database Service is dynamic, it will change if the cluster restarts. Kubernetes creates an internal DNS name for every Service:
initContainers:
- name: simple-chat-builder
image: diderikk/simple-chat-builder:v1.0.1
imagePullPolicy: IfNotPresent
envFrom:
- secretRef:
name: simple-chat-secrets
command: ["sh", '-c', 'mix ecto.setup'] # Executes migrations
After configuring the paths in the Ingress to correspond with the Services, both web applications communicate with my Kubernetes cluster:
ingressClassName: nginx
rules:
- host: elixirapi.me
http:
paths:
- path: /chesssocket
pathType: Prefix
backend:
service:
name: chess-service
port:
number: 4000
- path: /simplechatsocket
pathType: Prefix
backend:
service:
name: simple-chat-service
port:
number: 4000
- path: /api/simplechat
pathType: Prefix
backend:
service:
name: simple-chat-service
port:
number: 4000